In this post I will share some methods and scripts that helped me set and analyze the results of password cracking experiments using John the Ripper (john). During my Masters, I built a password guesser that learns the linguistic patterns of passwords used as training data. To prove these patterns pose a significant threat, I set up a number of guessing experiments (offline attacks) comparing the performance of my guesser with that of other guessers. In such experiments, the guesses are piped to john, which encodes them using the same hashing function used to encode the target hashes and checks how many passwords match. I was mainly interested in generating charts depicting the number of passwords guessed as a function of the number of guesses tried. It sounds simple, but john wasn’t really built with this academic use case in mind, so I had to use a few tweaks and hacks to get the job done.
In the examples below, I will be using JtR’s community enhanced version (1.8.0-jumbo-1), which has a few extra valuable features. You’ll find the scripts used here to generate charts and analysis at https://github.com/rafaveguim/jtr-lab-tools.
Charting
Let’s use as target the Battlefield hashes, and as wordlist the RockYou passwords.
If you run john in the conventional way, it prints a status line only when a key
is pressed in your keyboard. The status line contains what you need to generate a chart
of the cracking session: # of guesses tried, # of passwords cracked, time, etc.
To enable automatic output of the status line every n-th guess, you need to invoke
the external module AutoStatus. External modules are custom functions called by john,
and can be defined in john.conf, the global configuration file.
Download my custom john.conf and edit the variable interval in [List.External:AutoStatus]:
// Print the status line after every "interval" words tried
[List.External:AutoStatus]
int interval; // How often to print the status
int number; // Current word number
void init()
{
interval = 1000000; // Print the status line after every millionth guess.
number = 0;
}
void filter()
{
if (number++ % interval)
return;
status = 1; // Print the status line
}With this set, call john passing “AutoStatus” as value of the parameter --external:
./john --wordlist=rockyou.txt \
--rules \
--pot=rockyou_vs_bfield.pot \
--conf=john.conf \
--external=AutoStatus \
--format=Raw-MD5 \
bfield.hash 2> rockyou_vs_bfield.log
You get something like the following in output.log:
Press 'q' or Ctrl-C to abort, almost any other key for status
76260g 0:00:00:00 6.16% (ETA: 16:28:30) 143886g/s 1886Kp/s 1886Kc/s 366946MC/s cr4igh1ll..cprocks
88218g 0:00:00:00 12.71% (ETA: 16:28:30) 114568g/s 2597Kp/s 2597Kc/s 707745MC/s chelline..chellelynn
93495g 0:00:00:00 19.45% (ETA: 16:28:30) 96386g/s 3092Kp/s 3092Kc/s 1039GC/s vader125..vader02
96605g 0:00:00:01 26.67% (ETA: 16:28:33) 82568g/s 3418Kp/s 3418Kc/s 1368GC/s sharper3..sharpeiformulauno
99468g 0:00:00:01 33.84% (ETA: 16:28:32) 73138g/s 3676Kp/s 3676Kc/s 1694GC/s persian81..persian05
102037g 0:00:00:01 40.98% (ETA: 16:28:32) 65830g/s 3870Kp/s 3870Kc/s 2016GC/s mfaeez..mfac1640
104402g 0:00:00:01 48.17% (ETA: 16:28:32) 60001g/s 4022Kp/s 4022Kc/s 2337GC/s koukls..kouklaronaki86
106433g 0:00:00:01 55.18% (ETA: 16:28:31) 55433g/s 4166Kp/s 4166Kc/s 2655GC/s im14yrzold..i@m13inmay
109516g 0:00:00:02 62.45% (ETA: 16:28:33) 51903g/s 4265Kp/s 4265Kc/s 1485GC/s evazarate..evaylilian
112001g 0:00:00:02 69.61% (ETA: 16:28:32) 48696g/s 4347Kp/s 4347Kc/s 1642GC/s choclateice..CHOCLATE8
114602g 0:00:00:02 76.80% (ETA: 16:28:32) 46024g/s 4417Kp/s 4417Kc/s 1797GC/s army2id..army2528
116371g 0:00:00:02 83.67% (ETA: 16:28:32) 43748g/s 4511Kp/s 4511Kc/s 1951GC/s 6969kevin..6969it
118104g 0:00:00:02 90.19% (ETA: 16:28:32) 41585g/s 4577Kp/s 4577Kc/s 2104GC/s 2006slanger..2006SENIOR
119389g 0:00:00:03 97.61% (ETA: 16:28:33) 39796g/s 4666Kp/s 4666Kc/s 1504GC/s 066109573..066100732
119641g 0:00:00:03 DONE (2016-01-06 16:28) 38971g/s 4667Kp/s 4667Kc/s 1537GC/s ^^&\*()(..\`\`\`
Warning: passwords printed above might not be all those cracked
Use the "--show" option to display all of the cracked passwords reliably
Session completed
Other times you have, instead of a wordlist, a guess generator that will output as many guesses as possible; for instance, john’s incremental mode. In addition to printing status lines at regular intervals, in this case you also want to set a cap in the number of guesses of a john session. I use the AutoStatusAbort external:
[List.External:AutoStatusAbort]
int n, m, interval, limit, initial_value;
int scale; // defines the scale of the values (thousands, millions, etc.)
void init()
{
// the initial value is for the case we are running a multi-session attack;
// for instance, wordlist + incremental. In such case, initial_value should
// equal the number of guesses of the previous session.
// WARNING: don't change the format of the next line.
initial_value = 0; // AutoAbort
scale = 1000000;
if (initial_value > 0){
m = initial_value / scale;
n = initial_value % scale;
} else {
n = 0;
m = 0;
}
interval = 1; // How often print the status
limit = 80; // When to quit (80 * scale = 80 million)
}Let’s test it:
./john --incremental \
--pot=inc_vs_bfield.pot \
--conf=john.conf \
--external=AutoStatusAbort \
--format=Raw-MD5 \
bfield.hash 2> inc_vs_bfield.log
The next step is to produce a nice chart of your attack’s results. Let’s compare the two attacks we just ran:
python chart_logs.py -t 423623 -l 4 rockyou_vs_bfield.log inc_vs_bfield.log
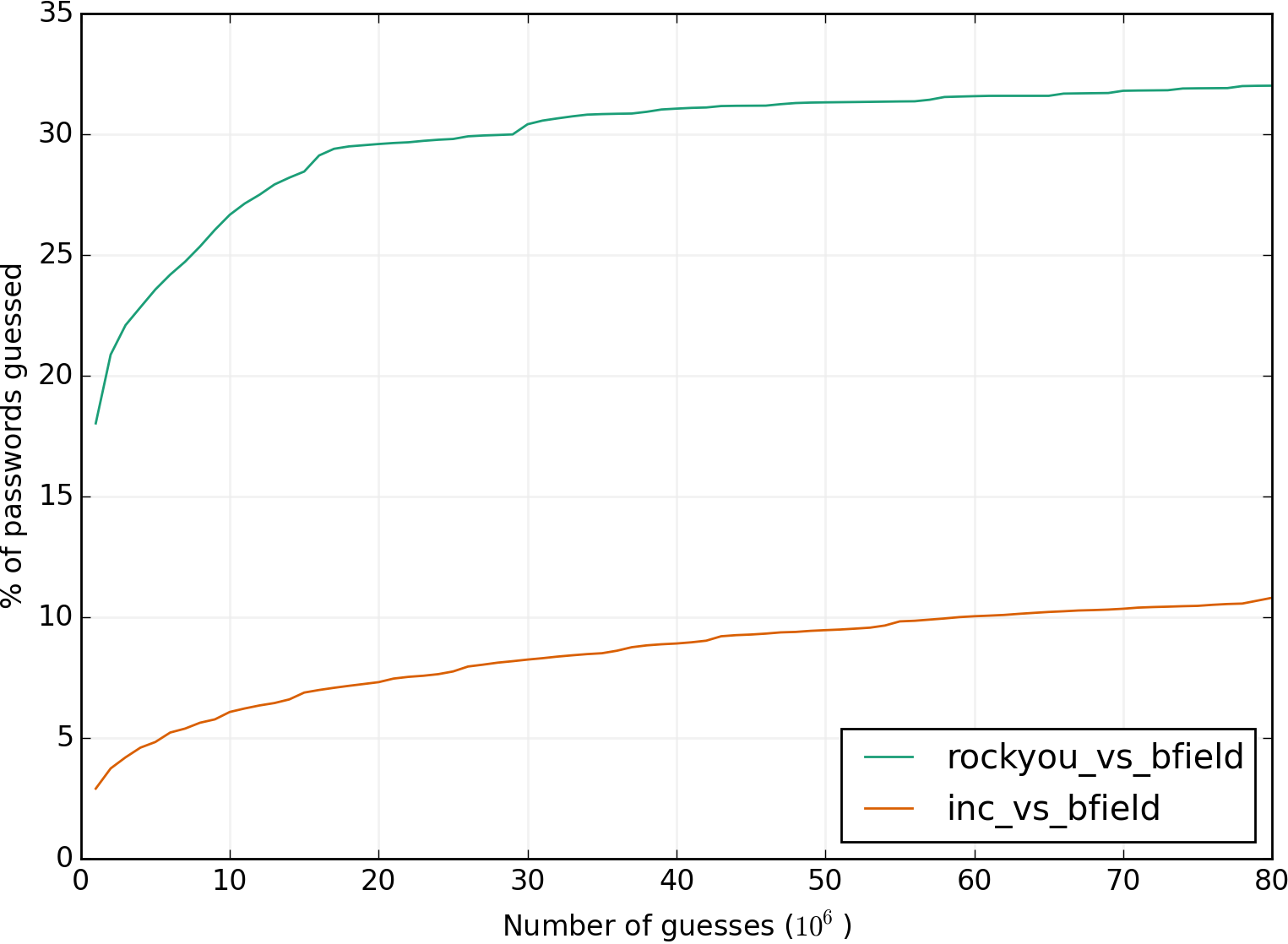
Run python chart_logs --help to see all parameters.
Automation and Reproducibility
Once the number of guessing experiments starts to grow, it’s challenging to keep a record of experiment variations and results. I keep things organized by encapsulating each experiment in a shell script accompanied by a john.conf file. My shell scripts follow the template below:
#!/bin/sh
# Summary: {Purpose, hypothesis, methods, materials, etc.}
# Date: {YYYY-MM-DD}
# Author: {John Doe}
#
# ASSUMPTIONS: {Any necessary external conditions (e.g., training data)}
location=$(pwd) # the current directory
target="" # path to target hashes
wordlist="" # guess list
john_dir="/opt/JohnTheRipper-bleeding-jumbo/run" # JohnTheRipper location
john_conf="" # path to configuration file
format="" # format of target hashes (e.g., Raw-SHA1-Linkedin)
jtr_lab_tools="" # jtr-lab-tools folder
"$john_dir/john" --wordlist=$wordlist --format=$format --pot=results.pot \
--config=$john_conf --external=AutoStatusAbort $target 2> "$location/results.log"
total_count=$(cat $target | wc -l)
# generate chart
python "$jtr_lab_tools/chart_logs.py" -t $total_count -l 4 "$location/results.log"Note that, for the sake of reproducibility, it’s important that each experiment have its own john.conf file. In addition, the parameter –pot (only available in the Jumbo version) tells john to use a local, session-exclusive .pot file, which stores the plain-text cracked passwords and is used by john to “remember” which passwords have been cracked. By default, john uses a global .pot file persisted across sessions. If you’re using the main version, which doesn’t have –pot, add a line to remove the global .pot file before each session.
Analyzing Password Composition
Finally, after the performance of each guessing attack has been compared, I
turn my attention to the nature of the passwords cracked by each attack.
For this purpose, I’ve written the script composition.py. It draws a chart
comparing the number of passwords cracked by each attack that match certain
composition requirements. These requirements are often used by websites to ensure
the creation of strong passwords, such as minimum length, and minimum number of
capital letters, numbers, and special characters. So the following analysis would
answer questions like: “If my website enforced password
creation policy X, how many passwords would be cracked under attack Y?”.
The input for composition.py is a list of .pot files and a list of password policies, each of which describing a minimum requirement. A policy is described as a simplified string pattern; for instance:
- ?????? - matches any password with 6 or more characters
- ??????123 - matches any password with at least 9 characters, at lest 3 of which must be numbers
- aaaaaa - any password with 6 or more lowercase alphabetic character
- ??11%%EE - minimum length 8, with two lowercase, two capital letters and two symbols
So, in the pattern, ? is a wildcard, % matches a symbol, and any digit, uppercase, or lowercase letter matches any digit, uppercase and lowercase letter, respectively. Let’s look into the passwords cracked by both attacks:
python composition.py \
rockyou_vs_bfield.pot inc_vs_bfield.pot \
-p abcdef 123456 aaaaa1 ????1% A?????
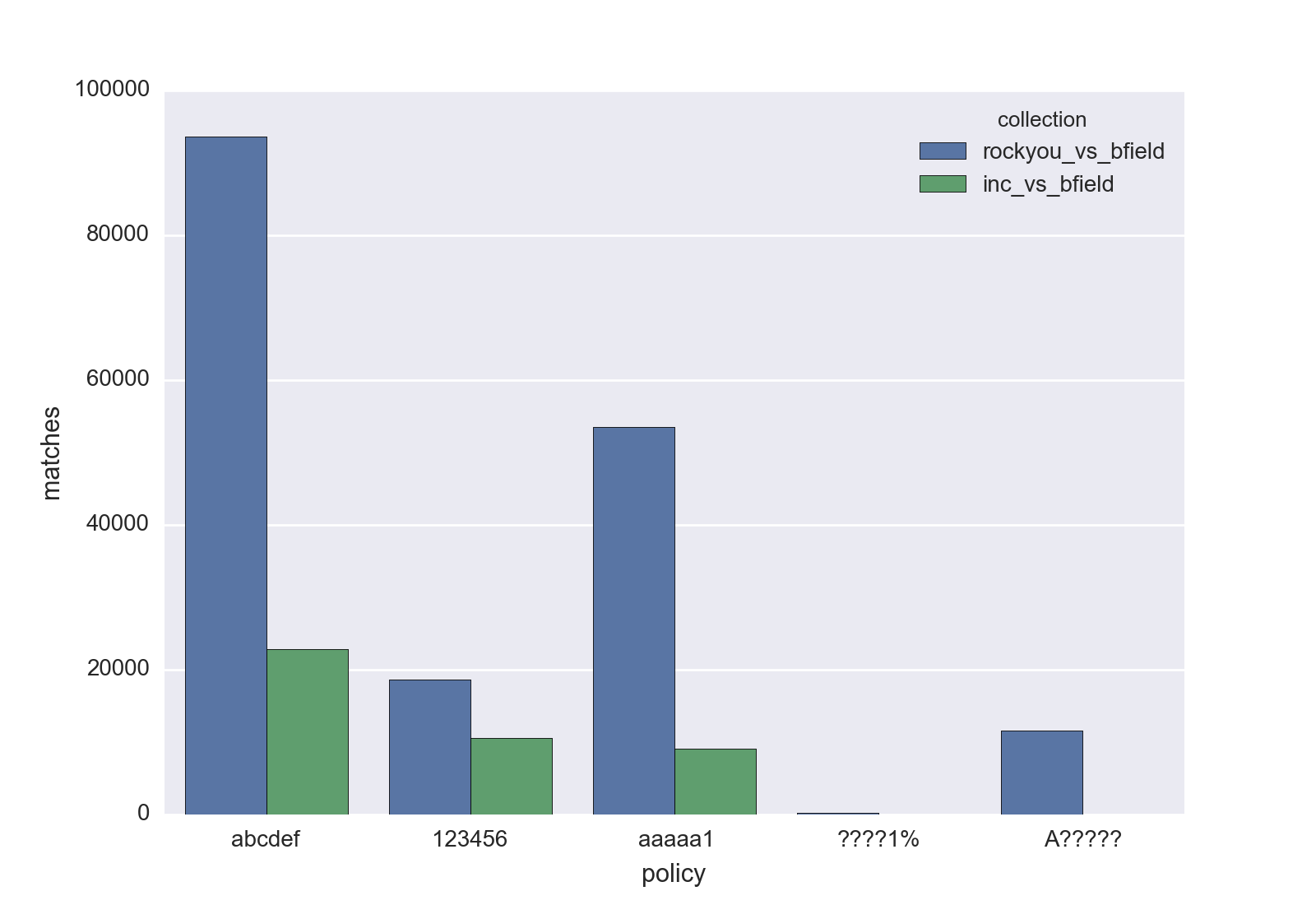
In this chart, we can see that, for all four kinds of passwords examined, the (mangled) RockYou guesses were more effective. The difference was a bit tighter for passwords with 6+ digits (e.g., 123456). Note that these are not counts for exact matches, as in a regular expression. A pattern here defines the minimum requirement for a password to be accepted, so “john111111” matches 123456, ??, aaaa, etc.
Final Thoughts
If you need more information, check Matt Weir’s blog and subscribe to john’s users mailing list, the folks there were extremely helpful when I needed. Drop me a line if you think I can help in any way.